更大,还能更快,更准!蚂蚁开源万亿参数语言模型Ling-1T,刷新多项SOTA
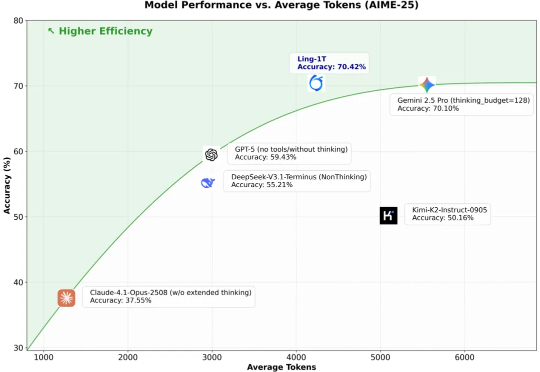
更大,还能更快,更准!蚂蚁开源万亿参数语言模型Ling-1T,刷新多项SOTA10 月 9 日凌晨,百灵大模型再度出手,正式发布并开源通用语言大模型 Ling-1T ——蚂蚁迄今为止开源的参数规模最大的语言模型。至此,继月之暗面Kimi K2、阿里 Qwen3-Max 之后,又一位重量级选手迈入万亿参数LLM 「开源俱乐部」。
来自主题: AI资讯
11367 点击 2025-10-09 11:47
 搜索
搜索
10 月 9 日凌晨,百灵大模型再度出手,正式发布并开源通用语言大模型 Ling-1T ——蚂蚁迄今为止开源的参数规模最大的语言模型。至此,继月之暗面Kimi K2、阿里 Qwen3-Max 之后,又一位重量级选手迈入万亿参数LLM 「开源俱乐部」。

国庆长假,AI 大模型献礼的方式是一波接一波的更新。OpenAI 突然发布 Sora2,DeepSeek 更新了 V3.2,智谱更新了 GLM-4.6,Kimi 则是更新了 App,然后默默在自己的版本记录里面,写下了这句话。

近日 Kimi 也开始小规模内测一个 Agent 新品,名称在一众 Agent 友商中,很有人文味与自信, 叫做:「OK Computer」。 阅尽千帆,本文仍想通过一系列典型 Agent 任务实测,为你解析 Kimi OK Computer 的真实水平。

Kimi发布全新Agent模型OK Computer !这个新Agent名字好像还有点儿来头啊……别的先不说,OK Computer到底OK不OK?实测一下!

今天,月之暗面正式发布全新 Agent,产品名别具一格:「OK Computer」。在大模型厂商进入战略对决关键时刻,这声“OK”,到底 O 不 OK?
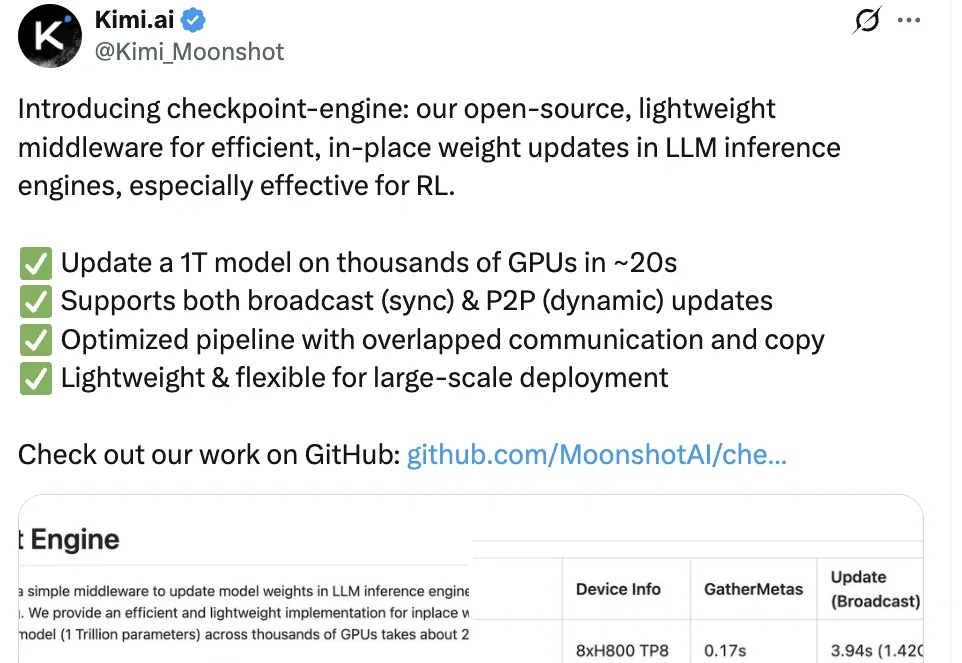
Kimi开源又双叒放大招了!
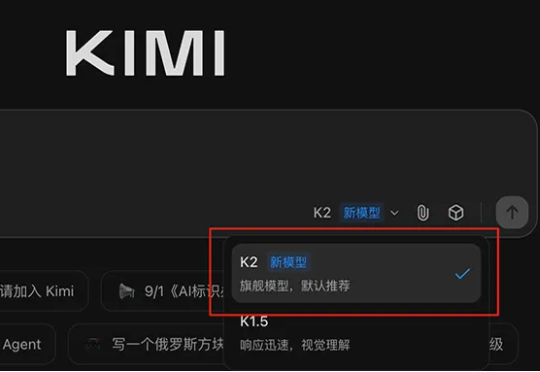
智东西9月5日消息,刚刚,大模型独角兽月之暗面发布新模型Kimi K2-0905,目前,Kimi应用和网页版中的K2模型已全量升级到Kimi K2-0905。该模型的核心升级点为Agentic Coding能力增强、支持256K上下文、API支持高达60-100Token/s的输出速度、支持Claude Code。
随着DeepSeek R1、Kimi K2和DeepSeek V3.1混合专家(MoE)模型的相继发布,它们已成为智能前沿领域大语言模型(LLM)的领先架构。由于其庞大的规模(1万亿参数及以上)和稀疏计算模式(每个token仅激活部分参数而非整个模型),MoE式LLM对推理工作负载提出了重大挑战,显著改变了底层的推理经济学。
这段时间 AI 编程的热度完全没退,一个原因是国内接连推出开源了不少针对编程优化的大模型,主打长上下文、Agent 智能体、工具调用,几乎成了标配,成了 Claude Code 的国产替代,比如 GLM-4.5、DeepSeek V3.1、Kimi K2。
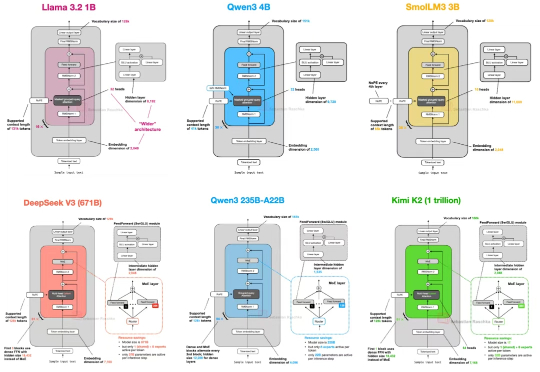
自首次提出 GPT 架构以来,转眼已经过去了七年。 如果从 2019 年的 GPT-2 出发,回顾至 2024–2025 年的 DeepSeek-V3 和 LLaMA 4,不难发现一个有趣的现象:尽管模型能力不断提升,但其整体架构在这七年中保持了高度一致。